
FaaS Is A Promising Architecture For Backends

Say you’re starting a startup today. How should you build your backend?
You should start by considering the highest level of abstraction, which is backend as a service. Which means Firebase. Say, after considering it, you find that it’s too high a level of abstraction for you, and you need to go one level lower.
That’s Functions as a Service. Let’s examine the different aspects of this architecture:
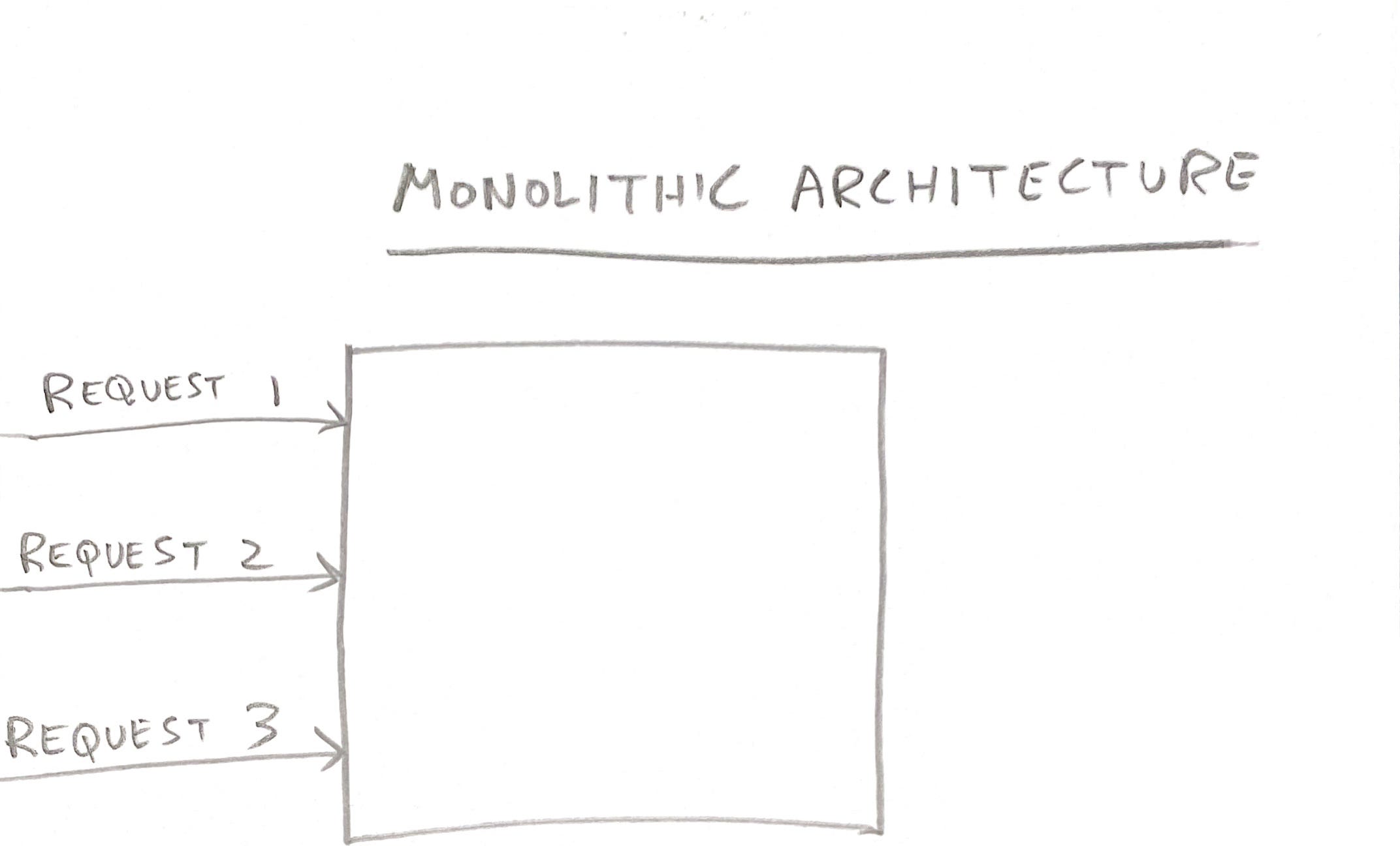
⦿ Modularity: A traditional backend mixes together code for all endpoints, as this infographic shows:

This makes it hard to understand. I’ve seen servers at Google where setting up the Guice dependencies goes on for pages. I could not form a mental model of how the server worked. This should not be surprising: we humans have a limited ability to handle complexity. FaaS solves that problem, relying on the builtin separation provided by HTTP endpoints:

Each Function will have only the code necessary for its functionality. If you have 100 Functions in your app, and you throw the code for all of them into a giant pot and stir it, it will be harder to understand.
One common misconception is that a monolith is best until a certain level of complexity. But just because a monolith can be made to work doesn’t mean it’s the best. Actually, we humans can handle only a very small amount of complexity before needing help in the form of decomposition. For example, if you have a Python function that goes on for 200 lines, you should see if it can be split into two functions to make it understandable. So, unless you’re building a Hello World app, FaaS results in better modularity, which is the main tool we have to contain complexity. Better modularity results in faster onboarding of new engineers, more understandable code, fewer bugs, and faster iteration than a monolith. A monolith is never the optimal solution.
⦿ Global variables: With Functions, you can use global variables for data that needs to be accessible in all sub-functions, since they’re scoped to that particular Function.
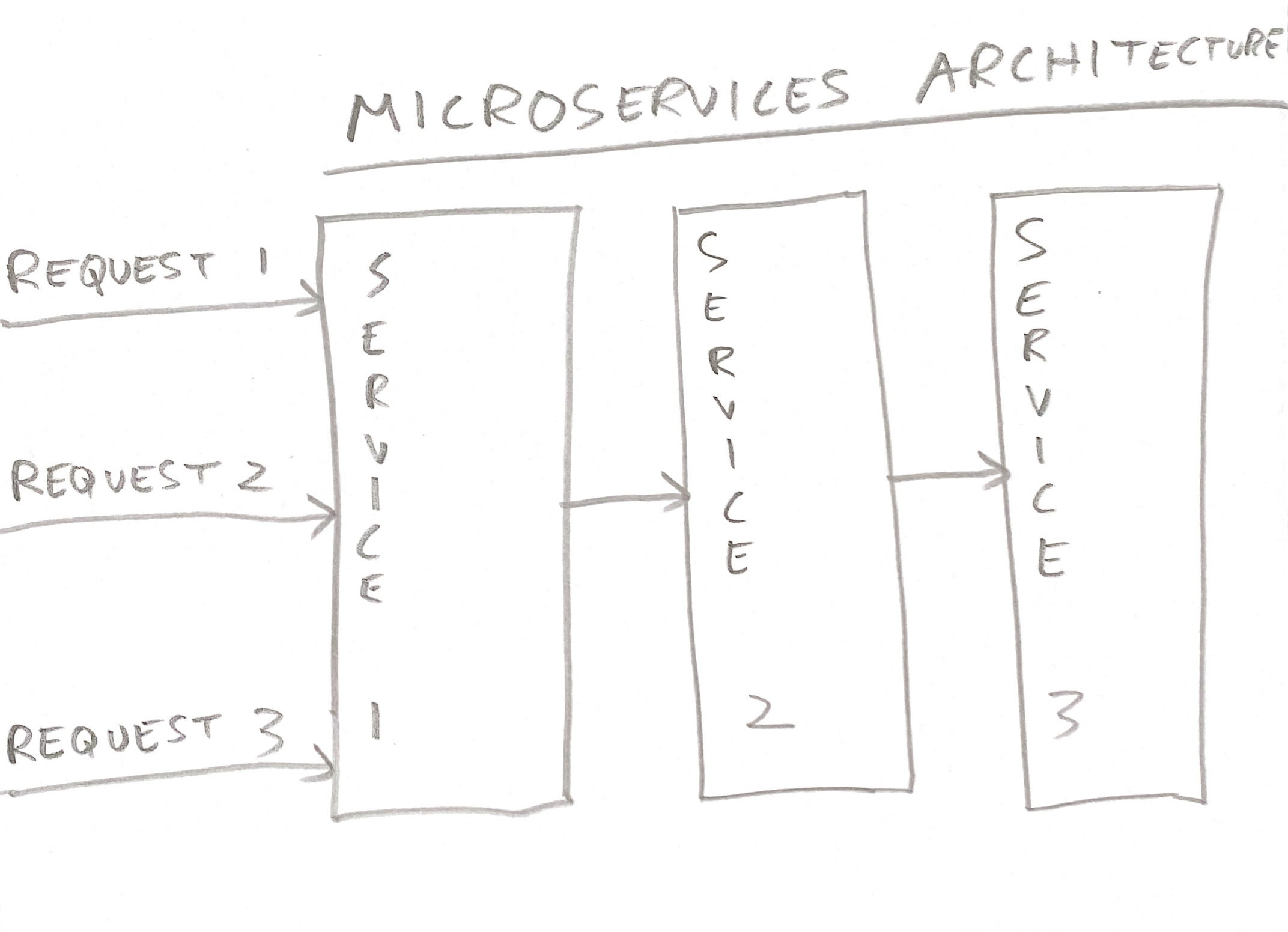
⦿ Better than microservices: FaaS is a better programming model than microservices, because a single HTTP request doesn’t need to bounce between multiple services, introducing multiple points of failure, latency, request routing, load balancing, and retries. Each of these can cause more complexity. For example, retries sound safe, but if you retry thrice at three layers of your system, you’re retrying 27 times! This can be enough to bring down the lowest layer of your system, like the database. All this fractal complexity is avoided in FaaS because each request essentially executes like a monolith. Different requests execute on different machines, but since each request executes on one machine, the above complexity is avoided:

⦿ Different languages: Different Functions can be coded in different languages. For example, if you’ve built your backend in JS, and then want to adopt machine learning for some new functionality, you may find it convenient to use Python. At that point, you can do so, changing only those endpoints that need ML, rather than all. You could argue that you should have chose Python to begin with, but you can’t foresee the future, so a flexible abstraction like Functions helps.
If you want to explore a new language, you can try it out with only one Function, knowing that if it fails, you can easily rewrite it in your older language. By contrast, trying out a new language in a traditional backend is riskier — you need to rewrite your entire backend, and you’re screwed if you chose wrong. As you invariably will, from time to time.
As a third example, imagine you built your Functions in Go, after which your frontend engineer needs to work on the backend to implement some more endpoints. He doesn’t know Go, and wonders if learning a new language is the best use of his time, as opposed to using the language he knows — Javascript. FaaS gives you more flexibility in that decision.
⦿ Wide and shallow architecture: FaaS makes sense when you have a wide and shallow architecture, as opposed to a narrow and deep architecture. That is, you have a bunch of HTTP endpoints with relatively self-contained logic. For example, a startup I worked with needed to email their users when they delete the app. This was done via a Function, which didn’t interact at all with the rest of the logic of the app. Many backends are like this, with a bunch of HTTP endpoints whose logic is closer to unrelated than to related to each other. If your backend is like this, FaaS is a good fit. Or, put differently, if your product is a CRUD app. In fact, I heard on a podcast that FaaS is the right architecture for such backends. Conversely, if your product is like Google search, with only a small interface, only one HTTP endpoint (/search) and a huge amount of backend complexity, with crawlers, ranking, abuse, connections to dozens of external data sources from weather to stock markets to everything else you can think of, then FaaS may not be the right architecture for your backend.
⦿ Concurrency: Concurrency can be a problem with traditional backends, because multiple requests can step on each other’s toes. Functions don’t receive concurrent requests, so you don’t need to synchronise access from multiple requests running at the same time.
⦿ Async: Traditional backends sometimes are coded using asynchronous APIs to process many requests using few threads. This makes the code less readable, risking bugs. Functions don’t need this optimisation, letting you use blocking APIs, which is more readable.
⦿ Caches: A long-running VM might have an in-memory cache, which opens up the possibility of the caches on multiple servers losing synchronisation. For example, imagine that a server receives a request to edit a user’s profile. The server updates the database and its in-memory cache. After editing, the user makes a request to read his profile, but the request happens to be routed to another server, whose cache is stale. The stale profile is shown to the user, making it seem like the edit didn’t work. The user will feel your system is broken, reducing his confidence in it. This problem of a stale cache is unlikely to happen with Functions, since they’re designed to be spun up on demand, execute, and terminate, so you don’t keep caches in the first place.
⦿ Deploying a traditional backend is risky, because you’re updating the code for (potentially) hundreds of endpoints at one go, and you could introduce a bug in any one of them. By contrast, deploying a Function is not risky, since the blast radius is low. If you do introduce a bug, with a traditional backend, you have to pore over scores of commits in your Git history to try to narrow it down. This is easier with a FaaS since there are fewer commits that affect each Function. If a deployment is buggy, rolling back a Function is less risky than rolling back a traditional backend, because in the latter case, you’re rolling back hundreds of endpoints, and something could go wrong in any of them.
⦿ Autoscaling: VMs don’t autoscale out of the box — you need to set up and configure autoscaling, and make sure that running multiple instaces of your backend doesn’t cause bugs (see the previous point). Functions autoscale out of the box, letting you focus on your business logic, as you should.
⦿ Canarying: FaaS has native support for canarying by sending a percentage of traffic to a canary version. You don’t need to use other layers like a load balancer to achieve this, because it’s native. If you’re using VMs (or containers), you can’t have clients connect to a single VM’s DNS name, because the traffic will go only to that VM. You need to put a load balancer in front. You don’t need this with Lambda since Lambda natively distributes traffic among multiple instances. Lambda also natively handles deploying new versions without downtime, which requires a separate CI/CD tool otherwise. Many architecture and DevOps issues are no longer issues with Lambda.
⦿ Provisioning a Function is easier than provisioning a VM. This is because VMs typically require more resources (CPU and memory) to process more requests, so it’s hard to give one answer to the question of how much are needed. It depends on how many requests it’s receiving. It also depends on the mix of requests, since some requests may be more demanding than others. On the other hand, an individual Function handles only one request at once, and only one type of request, so its resource requirements are easier to understand and model.
⦿ Overload: FaaS has a better worst-case behavior under load. An overloaded VM slows down, increasing latency, causing timeouts. Even if an error doesn’t occur, your users will lose patience if you take 40 seconds. Functions don’t slow down under load — they just spin up more instances, while maintaining the same latency. This is exactly the kind of behavior you want.
If the load gets even higher, a VM will crash, thus serving 0 requests successfully.
On the other hand, say you have a Function provisioned for 1000 simultaneous calls, but you encounter a load of 10,000. Then 9,000 requests will error out, but you’ll still successfully serve the 1000 you’re provisioned for. Which is better than the 0 a VM would serve:

⦿ Autonomy motivates people, and as managers, we need to think about how we can increase ownership for individual engineers. People respond positively when they’re trusted, when they’re given the keys to the car. FaaS lets you delegate responsibility for each Function to an individual engineer. For example, if a Function has high latency, first, we have visibility, as opposed to a traditional backend where the latency for all endpoints is mixed together and it’s hard to separate them. Second, the engineer in charge of that Function has both the authority and the responsibility to fix the problem, rather than “it’s someone else’s job”, which is an unhealthy attitude.
⦿ Availability: Both AWS Lambda and Google Cloud Functions run in multiple AZs, so even if one zone fails, your app is still available.
⦿ Security: FaaS can be more secure, since you can run different Functions under different service accounts that have different permissions. For example, in an e-commerce app, the edit_profile Function need not have permission to charge the customer. That way, if this Function is breached, attackers can’t use that to fraudulently charge customers.
⦿ Edge Functions: Functions, being lightweight and ephemeral, can be distributed closer to users, for lower latency, like a CDN, but for code rather than static assets. Rather than choosing one datacenter, resulting in high latency for most of your users, you want low latency for all your users, because every second of extra latency amounts to losing some users. Your code should execute closer to users. In addition to the user-visible benefit of latency, there’s also the benefit of reduced administration overhead: you shouldn’t have to choose which datacenter your code runs in, any more than you have to choose which power station to draw power from when you turn on your AC.
⦿ Cost: What about cost? Does FaaS cost so much as to become unviable? Let’s estimate, taking Telegram as an example. It has 36 million daily active users. Assume each user makes 100 HTTP requests a day. Let’s start with Google Cloud Functions. It offers different instance types with different amounts of CPU and memory. Let’s assume that we’ve optimised our code to use the cheapest. Then, GCF bills based on the time of execution, rounded up to 100ms. So let’s assume we’ve optimised all our functions to complete in 100ms. Assume also that each invocation returns 1KB. Incoming bandwidth is free, so we don’t need to consider it in this calculation. Taking all the above into account, GCF costs $84,000:
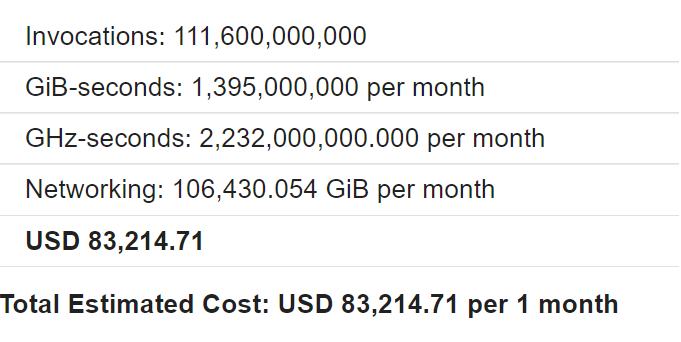
What if we use AWS Lambda instead of Google Cloud Functions? With the same assumptions, it works out cheaper, at $50,000.
$84,000 is actually a trivial amount to pay for a startup with hundreds of millions of users!
You should do a similar analysis for your startup to estimate costs. It will be inaccurate, but an order of magnitude estimation — is it $800/month? $8000? $80,000? $800,000? — is valuable for planning.
You should know what your costs are, and will be in the future, but don’t be cost-driven. Your job as a startup is to demonstrate business value, and you should use whatever technology helps you reach that goal the fastest. If you are miserly, others will move faster, and beat you. It would be like participating in a car race but driving slowly to conserve fuel, which is a guaranteed way to lose.
In summary, FaaS has a huge potential as the architecture of choice for most backends that can’t use BaaS, streamlining backend engineering.