
Why Client-server Won over P2P

Now that we use multiple devices, data needs to be synced among them. This can be done in two ways:
Client-server, where all clients sync with a central server.
Peer-to-peer, where devices sync with each other.
The client-server architecture won.
Why?
Because P2P introduces many intractable problems. Let’s look at them one by one. Here, a + means an advantage of the client-server architecture, while - means a drawback:
+ Data loss: In client-server, if you lose your device, you won’t lose your data — it’s still safe on the server.
+ Data size: In P2P, every device has to have all your data, which becomes prohibitive for bigger datasets like gigabytes. A lot of data is cold: you rarely access mails from years ago, so it’s not efficient to sync everything to all your devices just in case.
+ Online at the same time: If I open Google Keep on my laptop and add an entry to my shopping list, close my laptop, go to the supermarket and use my phone, I need to see my updated shopping list. In P2P, this may not work, since my laptop is offline at the time my phone is online. By contrast, servers are online all the time.
+ Better monitoring and debugging: Software has bugs and crashes, even those built by the smartest engineers. Centralising all data and logic on the server lets developers monitor, debug and fix problems better, including rolling out fixes instantly without waiting an unpredictable amount of time for client apps to update.
+ Performance: Some features like LLMs require a lot of computation that clients may not have, their batteries may drain, and their fans may spin up. Servers can have hardware acceleration like specific GPUs, NPUs and ASICs. The data may be too big for clients to handle, or may require too much latency to download or may exhaust cellular quota.
+ Trust: Some functionality like spam and abuse control has to live on the server. Some data is too sensitive to download to client devices. For example, Google Maps knows in real time the traffic on every road in the world. Google probably wouldn’t be okay sending this valuable data to client devices, because someone can make an app that pretends to be Google Maps and uploads this data to their server to run their own maps app.
+ Multiple conflict resolutions: With simultaneous or offline edits, the client-server architecture does conflict resolution in one place: the server. There’s one source of truth. Whereas, in the P2P architecture, if simultaneous edits were made on two devices A and B, both A and B have to do conflict resolution, which opens up the possibility that they reach different end states. For example, if one on one device you prepend “Apples” to your shopping list and and on the other, “Oranges”, in P2P, after sync, one device can show apples before oranges and the other the other way round. This is broken, since all devices are expected converge to the same final state. It doesn’t matter whether apples come before oranges as long as it’s the same on all devices. Worse, this lack of convergence makes subsequent conflict resolution worse: if you later add “Bananas”, you might have different devices showing:
Apples
Oranges
Bananas
Oranges
Apples
Bananas
Bananas
Apples
Oranges
Bananas
Oranges
Apples
Apples
Bananas
Oranges
Oranges
Bananas
Apples
As you can see, the number of states grows exponentially!
+ Multiple versions of the conflict resolution algorithm: A software update may roll out an updated conflict resolution algorithm. Since different devices update at different times, you could even have multiple algorithms fighting each other!
+ Compound syncs: Assume you have four devices A, B, C and D on which you’ve made edits. In client-server, since each device synchronises independently with the server, the four edits are applied one by one. That can happen in P2P, but P2P introduces another possibility: A and B sync with each other first, creating a resolved state AB. Independently, C and D sync with each other, creating a resolved state C and D. Then, AB and CD are synced with each other. This is a scenario we don’t have to worry about in client-server.
+ Bystanders: If two devices A and B have edits made at the same time, in P2P, a third device C on which no edits were made can receive conflicting updates from A and B, and therefore gets dragged into the conflict. On the other hand, in client-server, C receives only one update from the server. Since it had nothing to do with the conflict, it doesn’t need to worry about it.
+ Infinite loop: If you have three devices A, B and C on which you made simultaneous edits, in P2P, A might sync with B and C separately, and B with C, resulting in three resolved states AB, AC and BC. You started out with 3 states and ended up with 3. So you have to run the conflict resolution algorithm again, risking an infinite loop. A conflict resolution algorithm must produce fewer output states than inputs to avoid this, which happens naturally in client-server.
+ Linear revision history: Many apps like Google Docs have a revision history where you can see the sequence of edits made and restore the 4 PM version. This works naturally in client-server. On the other hand, in P2P, the revision history becomes branched:
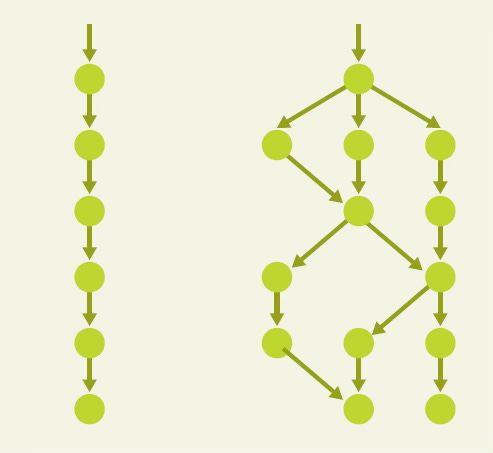
If someone wants to see what edits were made, it’s confusing. Restoring the 4 PM version becomes harder since there could be multiple 4 PM versions!
+ Analytics and compliance work better on the server.
- Privacy is the only argument for P2P1.
Considering all the intractable flaws of P2P, engineers won’t be able to write code that works correctly in so many scenarios, producing buggy, unreliable apps that corrupt your data. It’s no surprise that client-server is the universal solution.
But running your own server is a better solution.