
How to Model Data for NoSQL

This post is a summary of:
Except when otherwise specified, points in this post apply to all NoSQL databases, whether DynamoDB, MongoDB, Cassandra or other.
NoSQL databases are not suitable for analytics / OLAP, since they don’t do complex, ad-hoc queries. They’re not good at reshaping data on demand. NoSQL databases are meant for OLTP, which we’ll discuss in this post.
When you use any kind of database, you should think about how to model data. With an SQL database, whenever you find duplication of data, you extract it into another table. For example if you have an employee database:
You’d notice that Bangalore is in India for all employees, so this information should not be duplicated across Kartick and Ajo. You’d normalise it across two tables1:

and:

When a REST API call comes in, you JOIN these tables and return the result.
This is how you model data in an SQL database.
People often model data in NoSQL databases this way. When a new technology comes along, like NoSQL, people tend to use it the same way they did the old. That doesn’t work. New technology typically works in different ways.
To model data in a NoSQL database, you look at the REST API response you’re supposed to generate, and map that to a row in the database. You don’t JOIN multiple rows at query time; you precompute the JOIN and store the result in the database as one row, which you just read2 and return. So you have a 1:1 mapping between API responses and database rows. You don’t go back to the disk multiple times to read multiple rows to JOIN. This makes NoSQL scale better.
You may think that duplicating data is bad, but on the other hand, normalising it has multiple costs, too: high IOPS and CPU usage caused by the database reading multiple rows and joining them. This increases latency. Updating data split between multiple tables requires ACID transactions, which NoSQL databases don’t need as much.
Entities in a database often have different disparate types of data associated with them. For example, a customer in an e-commerce store has orders, with fields like order ID, order value and number of items in the order. In addition, the customer has customer info like name, phone number and city. In a relational database, you put them in two different tables, since each table has to have the same columns:

In a NoSQL database, you model it differently:

Notice that different rows have different fields. This is allowed in NoSQL. So you don’t need multiple tables to store different kinds of data like orders and customer info. You instead put them in one table.
Notice the nesting: customer contains two types of data: orders and customer info, each of which contains other fields. This is a hierarchical representation:
Customer
Order
Order ID
Order value
# items
Customer Info
Name
Phone Number
CityAs opposed to the relational representation where one table is not nested in another table; instead, the tables are all peers to each other and are linked via foreign keys.
In this example, the customer ID is called a partition key. NoSQL databases are sharded into partitions, each of which can be on a different server 3. This is how they scale. The partition key determines which partition a row falls into. A good partition key has high cardinality — it has many values. For example, user ID. A bad one has only a few values, like gender — this will cause all men to crowd onto one server, and all women to overload a second one, while the remaining servers sit idle because no data has been assigned to them.

As this infographic shows, another bad partition key is the timestamp rounded to a minute: this routes all requests to one server, taking it down, and next minute, takes down another server. You want a partition key that splits requests across servers evenly across time.
Sort Key
Moving on from the partition key, the sort key identifies each row within a partition. The combination of partition key and sort key must be unique. This explains why the sort key for order is of the form Order: 100, while the customer info’s sort key is just Customer Info without any numeric suffix. Each customer (partition) has only one customer info, but multiple orders.
You can do range queries based on the sort key, like <, since data is sorted in that order. Or starts with a given prefix. Or between a given lower and upper bound. Or in a given set of values. Or top 10.
Secondary Index
Sometimes you want to access the same date in two different orders. For example, in an e-commerce store, the user typically sees orders sorted by date, but may be able to sort by value. DynamoDB offers two types of secondary indices: local and global. With a local secondary index (LSI), the sort key could be different but the partition key must be the same. That is, each partition maintains a separate index. This lets you re-sort the data (within a partition) but not re-group it (across partitions).
Alternatively, a global secondary index (GSI) lets you both re-sort and re-group items. For example, each user sees his orders. Each order is assigned to a warehouse, and each warehouse needs to see a list of orders they need to fulfill. A GSI lets you re-group the data this way.
Query Filter
When you query DynamoDB, you can specify two filters. One is on the sort key. This is efficient because the data is stored sorted on disk, so you don’t have to read all the data to filter it. If it matches 10 rows out of 1000, DynamoDB will read closer to 10 rows than to 1000.
You can specify a second filter condition. This can be applied on any column but it’s inefficient because the data has to be read from disk and filtered. For example, if you’re tracking games:

The partition key is opponent, and the sort key is date. All games played with Bob are stored in one partition, so the WHERE Opponent='Bob' query is free. Similarly, the data is already stored sorted by date, so the ORDER BY Date is free. The FILTER ON is expensive, since it has to iterate through all the games played with Bob, which are the last three rows in the table, to return two. In this case it’s fine, but if there are 100 rows to iterate over to return two, it would be grossly inefficient.
Composite Keys
The alternative is to have a composite key StatusDate:

This assumes you’re interested in querying only a status, or a status along with a date, but never a date by itself. As long as this assumption holds, you can query it this way:
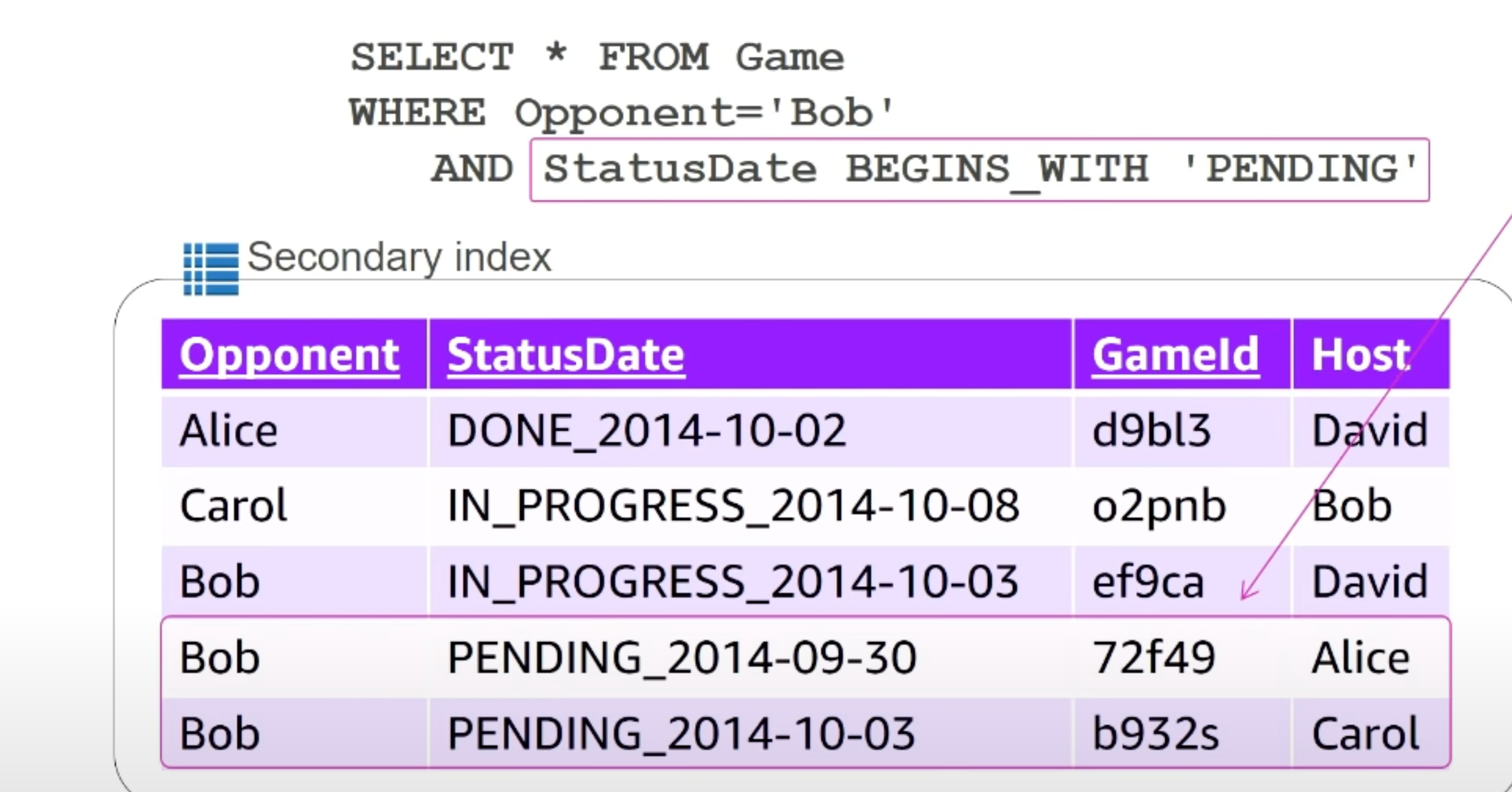
This removes the inefficiency of reading 100 rows from disk to filter them out and return only 2, which occurred earlier.
In general, if you have a composite key A_B_C, you can query for A, A along with B, or all three together. Basically, any prefix of A_B_C. This is no different from how folders on your computer work: if you organise your finances by creating a Year folder containing Credit Card Statements and Insurance Receipts and other kind of data for that year, you can access all data for a year (e.g., 2021/) or Credit Card Statements for a year (e.g., 2021/Credit Card Statements) but not Credit Card Statements across all years.
Taking a step back from all these details about data modeling with NoSQL, the key point is that if you’re using a NoSQL database, you should model your data differently from relational modeling.
Relational vs Non-relational Data?
Sometimes people say that if the data is relational, you should store it in a relational database and if not, you should store it in a NoSQL database. This doesn’t make sense: data is always relational. There are always relationships between different items. For example, an order is logically related to a customer. These relationships are what make the data valuable. So the question is not whether the data is relational, but whether you encode the relationships explicitly in an RDBMS, or implicitly in a NoSQL database.
Use an RDBMS If You’re Not Sure of Your Data Model
Sometimes people say that NoSQL is flexible. It’s actually less flexible than a relational database because the data should be structured to match the expected queries. If you’re not sure of your access patterns, if you can’t list the top 10 queries you’ll use, use an SQL database, which lets you re-shape the data at query time using JOINs and other complex queries.
Use an RDBMS if you’re not operating at scale
The key advantage of NoSQL is scale. If you’re not operating at an extreme scale, you’re not benefiting from NoSQL, but suffering its drawbacks. In such a case, use an SQL database like MySQL or Postgres. Everyone knows relational data modeling, and SQL to query it. People are familiar with associated tools like MySQL Workbench. Open-source databases don’t lock you into a cloud provider, unlike DynamoDB which is available only on AWS. Open-source databases don’t lock you into a managed service — you can always run it yourself on an EC2 VM, while DynamoDB is available only as a managed service. You can run an open-source database on your machine for development, or on premise. You can get an RDS instance with 1 TB memory and 128 vCPUs, which is more scale than 99% of startups need. In other words, NoSQL is an optimisation, and premature optimisation is the root of all evil.
As an aside, if this were a real application, you’d have to handle multiple cities with the same name in the same country. The UK has many Newports, for example.
NoSQL databases are often eventually consistent. Even those that offer strong consistency can default to eventual consistency, which is half the price (in DynamoDB).
NoSQL databases scale horizontally while SQL databases scale vertically.